

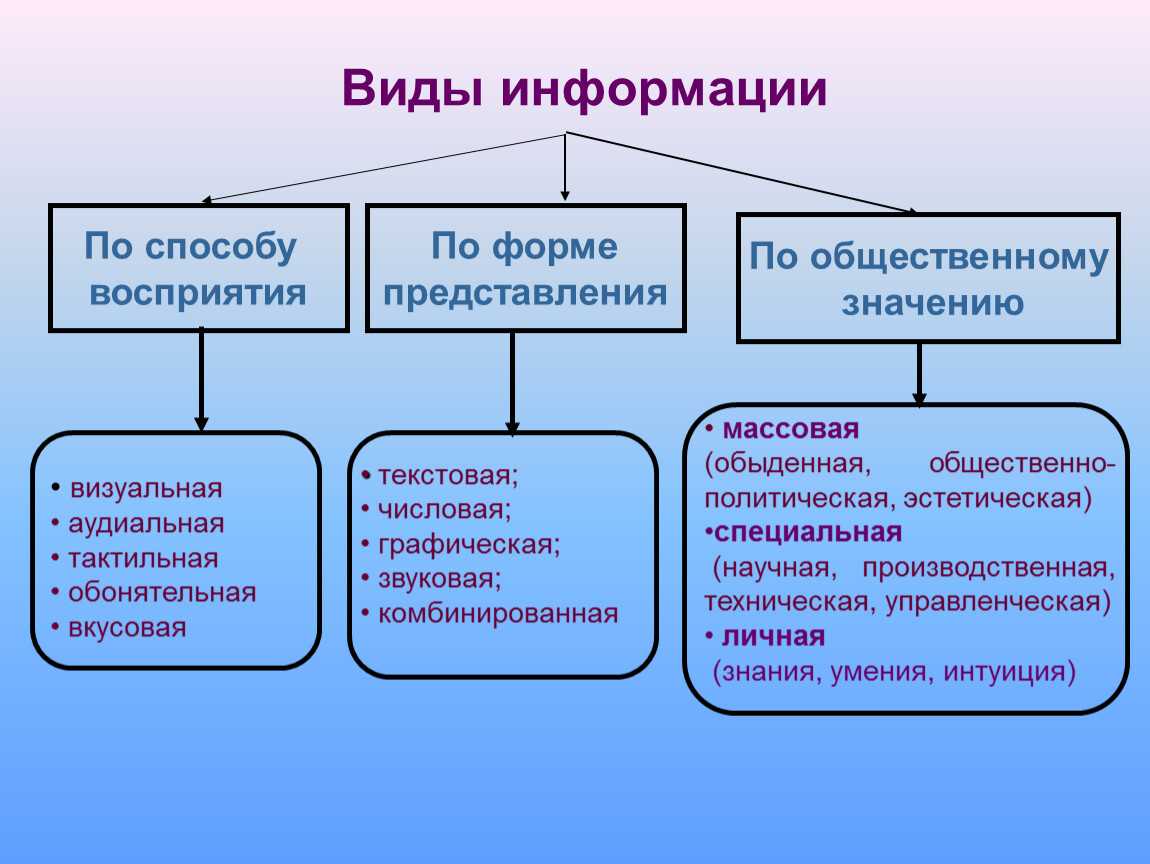
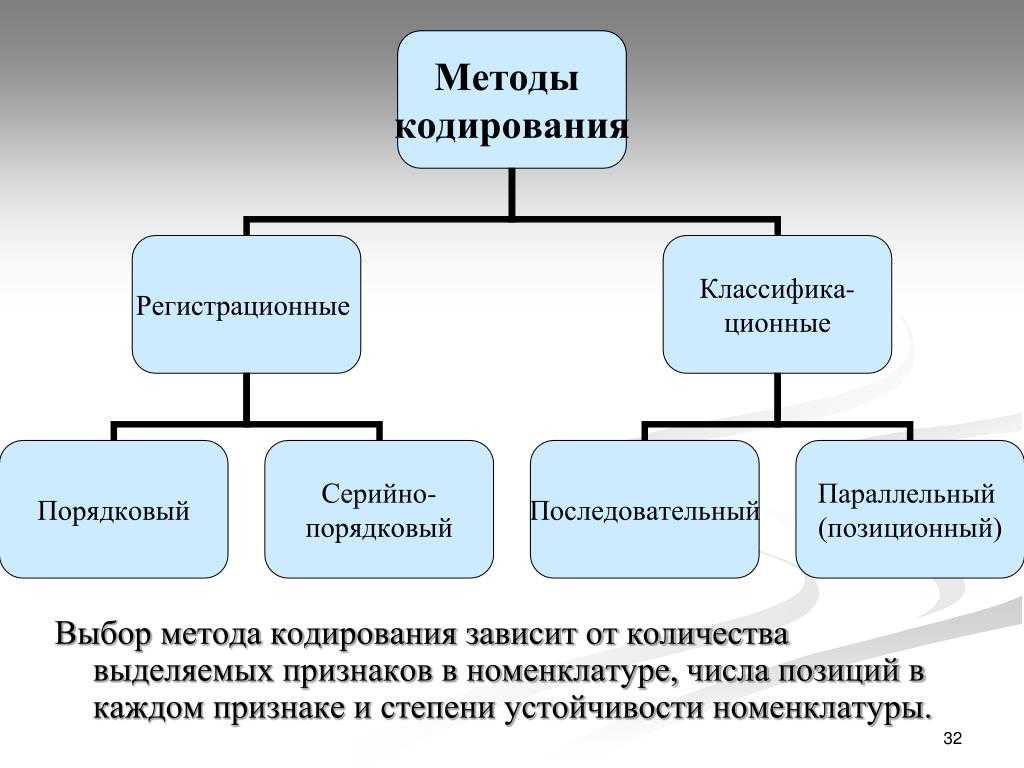
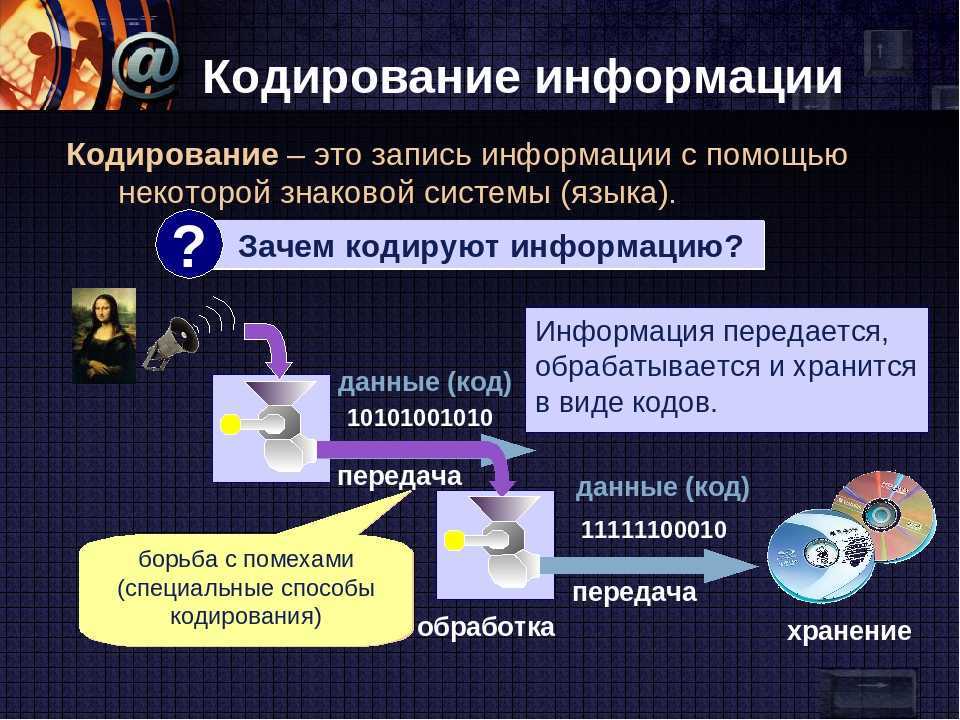
Кодирование графической информации
В видеопамяти находится двоичная информация об изображении, выводимом на экран. Почти все создаваемые, обрабатываемые или просматриваемые с помощью компьютера изображения можно разделить на две большие части — растровую и векторную графику.
Растровые изображения представляют собой однослойную сетку точек, называемых пикселами (pixel, от англ. picture element). Код пиксела содержит информации о его цвете.
Для черно-белого изображения (без полутонов) пиксел может принимать только два значения: белый и черный (светится — не светится), а для его кодирования достаточно одного бита памяти: 1 — белый, 0 — черный.
Пиксел на цветном дисплее может иметь различную окраску, поэтому одного бита на пиксел недостаточно. Для кодирования 4-цветного изображения требуются два бита на пиксел, поскольку два бита могут принимать 4 различных состояния. Может использоваться, например, такой вариант кодировки цветов: 00 — черный, 10 — зеленый, 01 — красный, 11 — коричневый.
На RGB-мониторах все разнообразие цветов получается сочетанием базовых цветов — красного (Red), зеленого (Green), синего (Blue), из которых можно получить 8 основных комбинаций:
| R | G | B | цвет |
|---|---|---|---|
| черный | |||
| 1 | синий | ||
| 1 | зеленый | ||
| 1 | 1 | голубой |
| R | G | B | цвет |
|---|---|---|---|
| 1 | красный | ||
| 1 | 1 | розовый | |
| 1 | 1 | коричневый | |
| 1 | 1 | 1 | белый |
Разумеется, если иметь возможность управлять интенсивностью (яркостью) свечения базовых цветов, то количество различных вариантов их сочетаний, порождающих разнообразные оттенки, увеличивается. Количество различных цветов — К и количество битов для их кодировки — N связаны между собой простой формулой: 2N = К.
В противоположность растровой графике векторное изображение многослойно. Каждый элемент векторного изображения — линия, прямоугольник, окружность или фрагмент текста — располагается в своем собственном слое, пикселы которого устанавливаются независимо от других слоев. Каждый элемент векторного изображения является объектом, который описывается с помощью специального языка (математических уравнения линий, дуг, окружностей и т. д.). Сложные объекты (ломаные линии, различные геометрические фигуры) представляются в виде совокупности элементарных графических объектов.
Объекты векторного изображения, в отличии от растровой графики, могут изменять свои размеры без потери качества (при увеличении растрового изображения увеличивается зернистость). Подробнее о графических форматах рассказывается в разделе «Графика на компьютере».
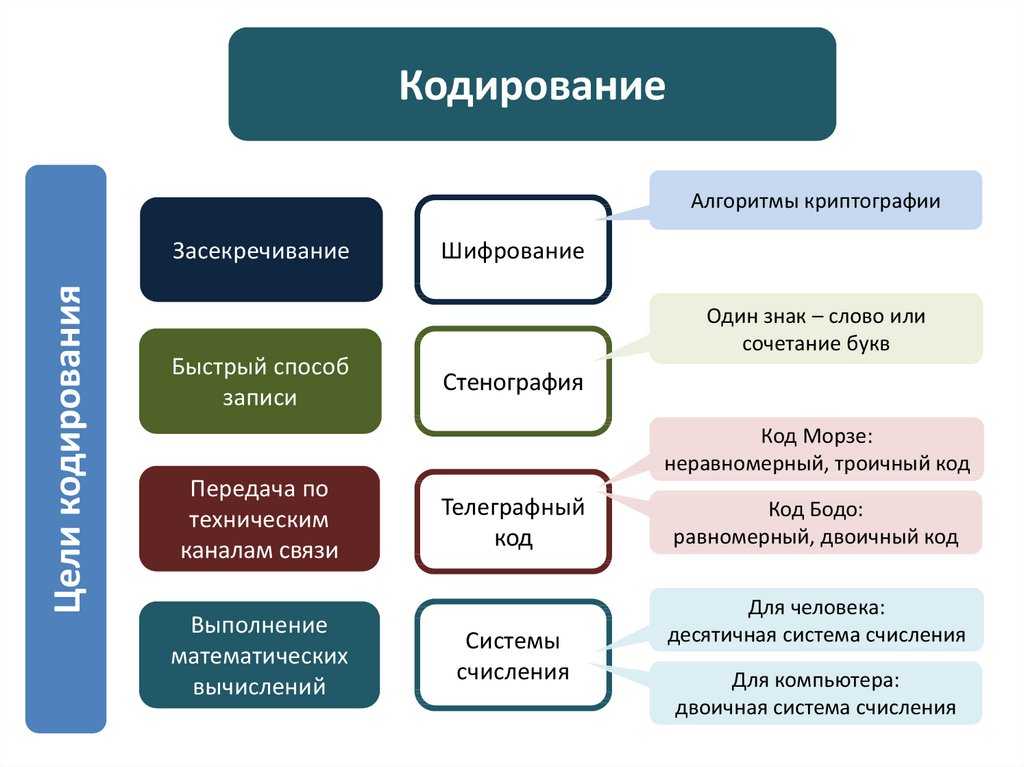
Шифрование
Часто возникает необходимость не только закодировать информацию, но и скрыть её содержимое от посторонних.
Для таких целей используется шифрование.
Простыми словами, шифрование – это кодирование информации, но не с целью её корректного представления на экране компьютера, а с целью сокрытия данных от тех, кому не положено получать доступ к шифрованной информации.
Алфавит шифрования состоит из двух элементов:
-
Алгоритм – уникальная последовательность математических действий с двоичными числами;
-
Ключ – бинарная последовательность, которая добавляется к шифруемому сообщению.
Дешифрование – это обратный процесс к защитному кодированию, который подразумевает превращение данных в первоначальный вид с помощью известного ключа.
Криптография – это наука о шифровании данных. Всего различают два раздела криптографии:
- Симметричная – в таких криптосистемах кодирования для шифрования и дешифрования используют один и тот же ключ. Недостаток системы – низкая стойкость ко взлому;
- Ассиметричная – для шифрования используются закрытый и открытый ключ. Таким образом, посторонний человек не сможет расшифровать (декодировать) сообщение, даже если алгоритм известен.
Где используется криптография?
Кодирование информации с целью шифрования используется уже более трех тысяч лет.
Истории известны первые попытки шифрованной передачи сообщений между известными полководцами царями и просто высокопоставленными людьми.
Сегодня без криптографии невозможно существование всей банковской системы, ведь каждая карта, каждая авторизация в онлайн-банкинге требует наличия защищенного соединения, при котором злоумышленник не сможет похитить ваши деньги или подобрать пароль.
К примеру, Telegram – мессенджер, главной особенностью которого является кодирование сообщений пользователей таким образом, чтобы никто посторонний не смог взломать переписку.
Также, алгоритмы шифрования встроены во все операционные системы, облачные хранилища.
Они нужны для защиты ваших личных данных.
![]()
Рис.7 – принцип работы защищенного соединения
Кодирование чисел
Существуют два основных формата представления чисел в памяти компьютера. Один из них используется для кодирования целых чисел, второй (так называемое представление числа в формате с плавающей точкой) используется для задания некоторого подмножества действительных чисел.
Множество целых чисел, представимых в памяти ЭВМ, ограничено. Диапазон значений зависит от размера области памяти, используемой для размещения чисел. В k-разрядной ячейке может храниться 2k различных значений целых чисел.
Чтобы получить внутреннее представление целого положительного числа N, хранящегося в k-разрядном машинном слове, необходимо:
- 1) перевести число N в двоичную систему счисления;
- 2) полученный результат дополнить слева незначащими нулями до k разрядов.
Пример
Получить внутреннее представление целого числа 1607 в 2-х байтовой ячейке.
Переведем число в двоичную систему: 160710 = 110010001112. Внутреннее представление этого числа в ячейке будет следующим: 0000 0110 0100 0111.
Для записи внутреннего представления целого отрицательного числа (-N) необходимо:
- 1) получить внутреннее представление положительного числа N;
- 2) обратный код этого числа заменой 0 на 1 и 1 на 0;
- 3) полученному числу прибавить 1.
Пример
Получим внутреннее представление целого отрицательного числа -1607. Воспользуемся результатом предыдущего примера и запишем внутреннее представление положительного числа 1607: 0000 0110 0100 0111. Инвертированием получим обратный код: 1111 1001 1011 1000. Добавим единицу: 1111 1001 1011 1001 — это и есть внутреннее двоичное представление числа -1607.
Формат с плавающей точкой использует представление вещественного числа R в виде произведения мантиссы m на основание системы счисления n в некоторой целой степени p, которую называют порядком: R = m * n p.
Представление числа в форме с плавающей точкой неоднозначно. Например, справедливы следующие равенства:
12.345 = 0.0012345 x 104 = 1234.5 x 10-2 = 0.12345 x 102
Чаще всего в ЭВМ используют нормализованное представление числа в форме с плавающей точкой. Мантисса в таком представлении должна удовлетворять условию: 0.1p <= m < 1p. Иначе говоря, мантисса меньше 1 и первая значащая цифра — не ноль (p — основание системы счисления).
В памяти компьютера мантисса представляется как целое число, содержащее только значащие цифры (0 целых и запятая не хранятся), так для числа 12.345 в ячейке памяти, отведенной для хранения мантиссы, будет сохранено число 12345. Для однозначного восстановления исходного числа остается сохранить только его порядок, в данном примере — это 2.
Кодирование звука
Из курса физики вам известно, что звук — это колебания воздуха. Если преобразовать звук в электрический сигнал (например, с помощью микрофона), мы увидим плавно изменяющееся с течением времени напряжение. Для компьютерной обработки такой — аналоговый — сигнал нужно каким-то образом преобразовать в последовательность двоичных чисел.
Поступим следующим образом. Будем измерять напряжение через равные промежутки времени и записывать полученные значения в память компьютера. Этот процесс называется дискретизацией (или оцифровкой), а устройство, выполняющее его — аналого-цифровым преобразователем (АЦП).
Оцифровка звука
Для того чтобы воспроизвести закодированный таким образом звук, нужно выполнить обратное преобразование (для него служит цифро-аналоговый преобразователь — ЦАП), а затем сгладить получившийся ступенчатый сигнал.
Чем выше частота дискретизации (т. е. количество отсчетов за секунду) и чем больше разрядов отводится для каждого отсчета, тем точнее будет представлен звук. Но при этом увеличивается и размер звукового файла. Поэтому в зависимости от характера звука, требований, предъявляемых к его качеству и объему занимаемой памяти, выбирают некоторые компромиссные значения.


Описанный способ кодирования звуковой информации достаточно универсален, он позволяет представить любой звук и преобразовывать его самыми разными способами. Но бывают случаи, когда выгодней действовать по-иному.
Человек издавна использует довольно компактный способ представления музыки — нотную запись. В ней специальными символами указывается, какой высоты звук, на каком инструменте и как сыграть. Фактически, ее можно считать алгоритмом для музыканта, записанным на особом формальном языке. В 1983 г. ведущие производители компьютеров и музыкальных синтезаторов разработали стандарт, определивший такую систему кодов. Он получил название MIDI.
Конечно, такая система кодирования позволяет записать далеко не всякий звук, она годится только для инструментальной музыки. Но есть у нее и неоспоримые преимущества: чрезвычайно компактная запись, естественность для музыканта (практически любой MIDI-редактор позволяет работать с музыкой в виде обычных нот), легкость замены инструментов, изменения темпа и тональности мелодии.
Стандарты кодирования графических данных
Чтобы закодировать изображение требуется гораздо больше байт, чем для кодирования символов. Большинство созданных и обработанных изображений, хранящихся в памяти компьютера, разделяют на две основные группы:
- изображения растровой графики;
- изображения векторной графики.
Растровая графика
В растровой графике изображение представлено набором цветных точек. Такие точки называют пикселями (pixel). При увеличении изображения такие точки превращаются в квадратики.
Для кодирования чёрно-белого изображения каждый пиксель кодируется одним битом. К примеру, чёрный цвет — 0, а белый — 1)
Наше прошлое изображение можно закодировать так:
При кодировании нецветных изображений чаще всего применяют палитру из 256 оттенков серого, начиная от белого и заканчивая чёрным. Поэтому для кодирования такой градации достаточно одного байта (28=256).
В кодирования цветных изображений применяют несколько цветовых схем.
На практике, чаще применяют цветовую модель RGB, где соответственно используется три основных цвета: красный, зелёный и синий. Остальные цветовые оттенки получаются при смешивании этих основных цветов.
Таким образом, для кодирования модели из трёх цветов в 256 тонов, получается свыше 16,5 миллионов разных цветовых оттенков. То есть для кодирования применяют 3⋅8=24 бита, что соответствует 3 байтам.
Естественно, что можно использовать минимальное количество бит для кодирования цветных изображений, но тогда может быть образовано и меньшее количество цветовых тонов, в связи, с чем качество изображения существенно понизится.
Чтобы определить размер изображения нужно умножить количество пикселей в ширину на длину количество пикселей и ещё раз умножить на размер самого пикселя в байтах.
I=a*b*i
Где
- а — количество пикселей в ширину;
- b — количество пикселей в длину;
- I – размер одного пикселя в байтах.
К примеру, цветное изображение размером 800⋅600 пикселей, занимает 60000 байт.
Векторная графика
Объекты векторной графики кодируются совершенно по-другому. Здесь изображение состоит из линий, которые могут иметь свои коэффициенты кривизны.
«Кодирование и декодирование информации»
Код ОГЭ: 1.2.2 Кодирование и декодирование информации.
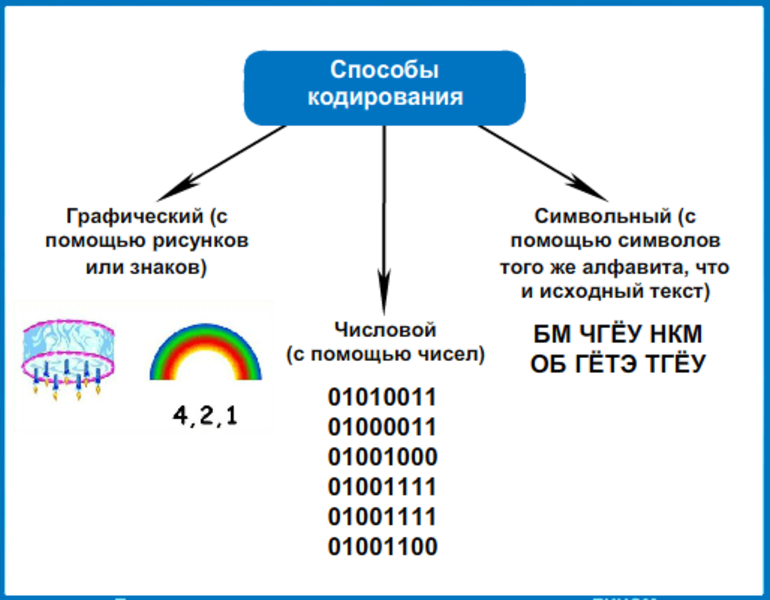
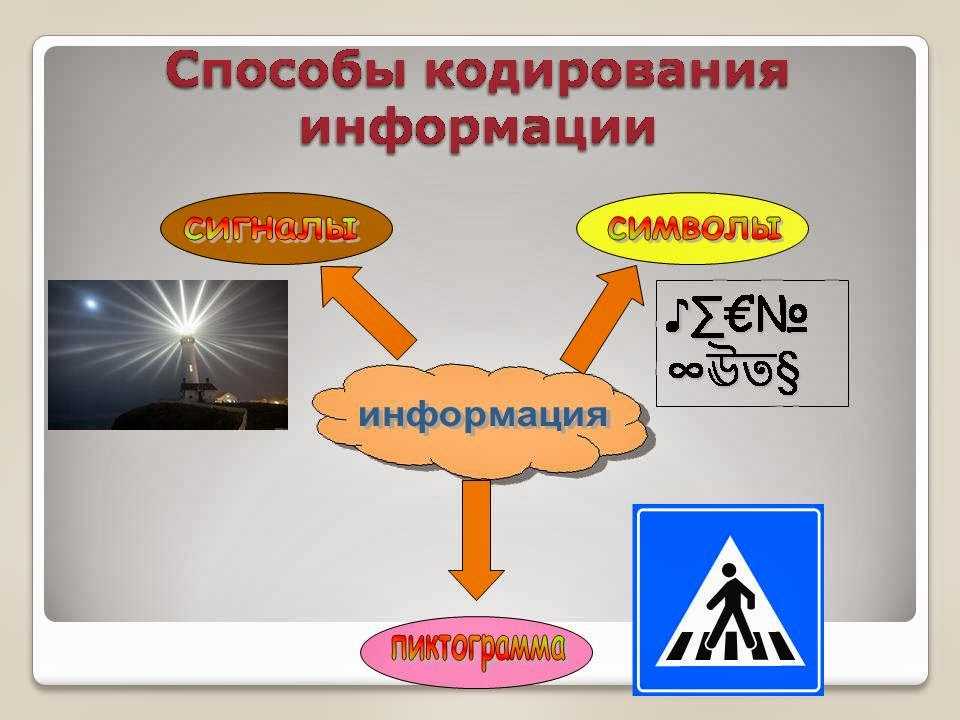
Кодирование информации
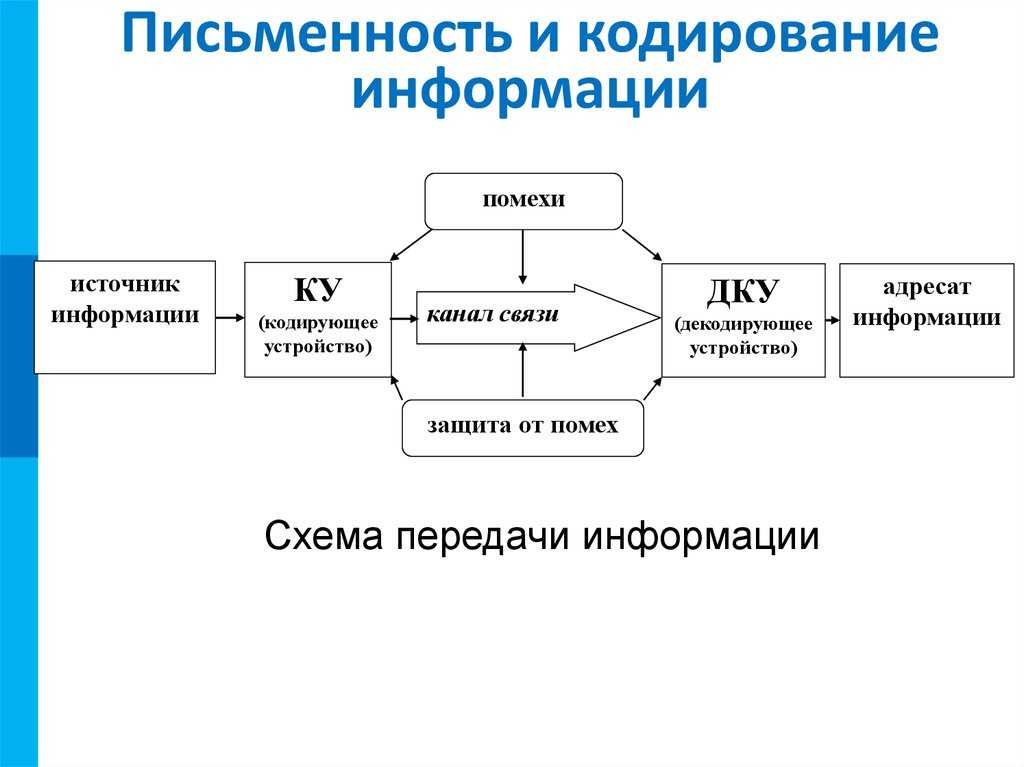
■ Кодирование информации — процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки.
В процессах восприятия, передачи и хранения информации живыми организмами, человеком и техническими устройствами происходит кодирование информации. В этом случае информация, представленная в одной знаковой системе, преобразуется в другую. Каждый символ исходного алфавита представляется конечной последовательностью символов кодового алфавита. Эта результирующая последовательность называется информационным кодом (кодовым словом, или просто кодом).
Примерами кодов являются последовательность букв в тексте, цифр в числе, двоичный компьютерный код и др.
Код состоит из определенного количества знаков (имеет определенную длину), которое называется длиной кода. Например, текстовое сообщение состоит из определенного количества букв, число — из определенного количества цифр.
Преобразование знаков или групп знаков одной знаковой системы в знаки или группы знаков другой знаковой системы называется перекодированием.
При кодировании один символ исходного сообщения может заменяться одним или несколькими символами нового кода, и наоборот — несколько символов исходного сообщения могут быть заменены одним символом в новом коде. Примером такой замены служат китайские иероглифы, которые обозначают целые слова и понятия.
Кодирование может быть равномерным и неравномерным. При равномерном кодировании все символы заменяются кодами равной длины; при неравномерном кодировании разные символы могут кодироваться кодами разной длины (это затрудняет декодирование). Неравномерный код называют еще кодом переменной длины.
Примером неравномерного кодирования является код азбуки Морзе. Длительное время он использовался для передачи сообщений по телеграфу. Кодовый алфавит включал точку, тире и паузу. При передаче по телеграфу точка означала кратковременный сигнал, тире — сигнал в 3 раза длиннее. Между сигналами букв одного слова делалась пауза длительностью одной точки, между словами — длительностью трех точек, между предложениями — длительностью семи точек.
Вначале код Морзе был создан для букв английского алфавита, цифр и знаков препинания. Принцип этого кода заключался в том, что часто встречающиеся буквы кодировались более простыми сочетаниями точек и тире. Это делало код компактным. Позже код был разработан и для символов других алфавитов, включая русский.
Коды Морзе для некоторых букв.
![]()
Чтобы избежать неоднозначности, код Морзе включает также паузы между кодами разных символов.
Декодирование информации
■ Декодирование — обратный процесс восстановления информации из закодированного представления.
В зависимости от системы кодирования информационный код может или не может быть декодирован однозначно. Равномерные коды всегда могут быть декодированы однозначно.
Для однозначного декодирования неравномерного кода важно, имеются ли в нем кодовые слова, которые являются одновременно началом других, более длинных кодовых слов. Закодированное сообщение можно однозначно декодировать с начала, если выполняется условие Фано: никакое кодовое слово не является началом другого кодового слова
Закодированное сообщение можно однозначно декодировать с начала, если выполняется условие Фано: никакое кодовое слово не является началом другого кодового слова.
Закодированное сообщение можно однозначно декодировать с конца, если выполняется обратное условие Фано: никакое кодовое слово не является окончанием другого кодового слова.
Неравномерные коды, для которых выполняется условие Фано, называются префиксными. Префиксный код — такой неравномерный код, в котором ни одно кодовое слово не является началом другого, более длинного слова. В таком случае кодовые слова можно записывать друг за другом без разделительного символа между ними.






Например, код Морзе не является префиксным — для него не выполняется условие Фано. Поэтому в кодовый алфавит Морзе, кроме точки и тире, входит также символ–разделитель — пауза длиной в тире. Без разделителя однозначно декодировать код Морзе в общем случае нельзя.
Конспект урока по информатике «Кодирование и декодирование информации».
Вернуться к Списку конспектов по информатике.
Код
| Определение: |
| Пусть — множество исходных символов, — кодовый алфавит, — множество всех строк конечной длины из .Код (англ. code) — отображение и так, что |
Виды кодов
- Код фиксированной длины (англ. fixed-length code) — кодирование каждого символа производится с помощью строк одинаковой длины. Также он называется равномерным или блоковым кодом.
- Код переменной длины (англ. variable-length code) — кодирование производится с помощью строк переменной длины. Также называется неравномерным кодом
Префиксный код — код, в котором, никакое кодовое слово не является началом другого. Аналогично, можно определить постфиксный код — это код, в котором никакое кодовое слово не является концом другого.
.
Все вышеперечисленные коды являются — для такого кода любое слово, составленное из кодовых слов, можно декодировать только единственным способом.
Примеры кодов
- — блочный.
- Код Хаффмана (англ. Huffman code) — префиксный.
- Азбука Морзе — не является ни блочным, ни префиксным, тем не менее, однозначно декодируемый засчет использования пауз.
Кодирование видеозаписи
Видеозапись состоит из двух компонентов: звукового и графического.
Кодирование звуковой дорожки видеофайла в двоичный код осуществляется по тем же алгоритмам, что и кодирование обычных звуковых данных. Принципы кодирования видеоизображения схожи с кодированием растровой графики (рассмотрено выше), хотя и имеют некоторые особенности. Как известно, видеозапись — это последовательность быстро меняющихся статических изображений (кадров). Одна секунда видео может состоять из 25 и больше картинок. При этом, каждый следующий кадр лишь незначительно отличается от предыдущего.
Учитывая эту особенность, алгоритмы кодирования видео, как правило, предусматривают запись лишь первого (базового) кадра. Каждый же последующий кадр формируются путем записи его отличий от предыдущего.
Кодирование изображения
Возьмем к примеру небольшое черно-белое изображение:
Представим, что это изображение разлиновали вертикальными и горизонтальными линиями, иначе говоря, наложили на нее мелкую сетку (растр):
![]()
То есть, у нас получилось мозаика из черных и белых квадратиков, называемых пикселями. Пиксель — термин, образованный сокращением фразы picture element. Если поставить в соответствие черному пикселю 0, а белому — 1 , то можно закодировать это изображение, записав подряд все нули и единицы, соответствующие пикселям этого изображения. Такой способ кодирования изображения называется растровым.
Если для пикселя использовать не один бит, а восемь, то можно закодировать цветное изображение, где каждый пиксель, может быть окрашен в один из 256 цветов. Количество бит, предусмотренных для пикселя называется глубиной цвета. А ширина и высота изображения в пикселях — разрешающей способностью.
В современных компьютерных системах для пикселя отводят 3 байта, один байт для каждого из основных цветов: красного, зеленого и синего. То есть 24 бита обеспечивают представление 224 = 16 777 216 цветов.
Для того, чтобы рассчитать количество бит, необходимых для кодирования изображения, нужно умножить глубину цвета (количество бит пикселя) на ширину и высоту изображения в пикселях.
Задача: Какой объем видеопамяти в байтах требуется для хранения растрового изображения, занимающего весь экран монитора с разрешающей способностью 640×480 пикселей, если используется палитра из 65536 цветов?
Решение: Глубина цвета составляет log265536 = 16 бит. Следовательно для хранения одно пикселя требуется 2 байта. Объем видеопамяти: 640⋅ 480⋅ 2 = 614400 байт.
Недостатки двоичного кода
Сложность чтения. Записанная с помощью 0 и 1 информация нечитаема для человека, не обладающего специальными знаниями и обучения. Расшифровка двоичного кода на понятный язык может быть очень сложной и требует использования специальных методов и программ.
Высокая сложность программирования. Написание программы на двоичном коде невозможно без глубокого понимания и экспертизы в области низкоуровневого программирования. Это требует большого количества усилий и времени, особенно для составления длинных и сложных программ.
Ограниченная емкость. Двоичное представление требует больше символов для тех же данных по сравнению с другими системами кодирования. Это может привести к увеличению размера файла или затратам на дополнительное хранение.
Сложность визуализации. Двоичный код трудно визуализировать, особенно для больших наборов данных. Это может затруднять его отслеживание и анализ без использования специальных инструментов и программ.
Таким образом, двоичное кодирование информации остается на данный момент основным способом, используемым в вычислительных устройствах. На нем основана вся логическая архитектура смартфонов, планшетов, ПК, огромных суперкомпьютеров, бортовых вычислительных систем самолетов, космических аппаратов, кораблей и т. д. Тем не менее у него есть недостатки, которые ограничивают развитие компьютерной техники. Возможно, в связи с экспоненциальным ростом потребности в эффективной обработке информации в будущем бинарный код уступит место альтернативным способам кодировки.
Другие термины на «Д»
ДампДоменДрайверДедлайнДисперсияДекомпозиция
Все термины
Разновидности
Символы можно «зашифровывать» несколькими способами. Все зависит от того, какой операционной системой на данный момент пользуется клиент. Если на двух устройствах задействованы разные таблицы символов, существует вероятность появления при декодировании непонятных графических интерпретаций – «кракозябр».
Основными кодировками в IT в 21 веке выступают следующие варианты:
- ASCII;
- Unicode (UTF-8 /16/32);
- KOI8-R;
- CP866;
- Windows 251.
В современных компьютерах чаще всего используются ASCII и Юникод (UTF-8 /16). С ними проще всего работать. Данные наборы символов умеют распознавать практически все алфавиты, включая русские буквы (кириллицу).
ASCII – базовый тип
Далее каждый «набор символов» будет изучен более подробно
Особое внимание будет уделено кодировке UTF. ASCII – это «базовый набор символов»
Он используется при работе основной массы устройств. Здесь первые 128 символов – наиболее распространенные. Они поддерживают:
- арабские буквы;
- знаки препинания;
- служебные элементы;
- латинские буквы.
При использовании ASCII задействован всего один байт. Такой подход привел к тому, что у упомянутого набора символов появились более «обширные» версии. Классическая форма представления ASCII не предусматривают работу с русскими символами, а также с кириллицей.
![]()
Выше – стандартные элементы ASCII. Они значительно отличаются от UTF-8 и других символьных наборов.
Расширенные ASCII
ASCII – это основа всех кодировок, которые известны в 21 веке. В «классической» ее форме поддерживаются 128 элементов. В расширенной – 256. Такой подход позволил добавлять новые алфавиты и символьные записи для отображения на экранах в будущем.





Первый вариант расширенного ASCII – CP866. Она поддерживает латиницу и кириллицу. Верхняя часть совпадает с ASCII, нижняя – дает перспективы «шифрования» кириллицы и некоторых специальных компонентов. Таких, которых нет на клавиатуре.
Еще один расширенный вариант – KOI8-R. Не стоит путать его с UTF-8. Второй расширенный вариант ASCII поддерживает «трансформацию» символов одним байтов. В KOI8-R буквы русского языка расположены не «по алфавиту». Здесь они размещаются по созвучию с кириллицей.
Windows 1251
Развитие систем «шифрования» символов напрямую связывается с совершенствованием графических компонентов в операционных системах. Необходимость в псевдографике пропала. Это привело к тому, что возникли группы, ранее выступающие в виде расширенных ASCII, но с большим уровнем совершенности. В них отсутствовали псевдографические компоненты. Они стали называться ANSI. Позже появился Юникод и UTF 8.
Наиболее распространенный вариант ANSI – это Windows 1251. Он:
- вместо псевдографики предлагает недостающие кириллические компоненты и русскую топографику;
- не имеет знака ударения;
- первые 32 составляющие – это операции, пробел и перевод строки;
- до 127 компонента будут располагаться: латинский алфавит, цифры, знаки математических действий и препинания;
- оставшиеся «пространства» отводятся для национальных алфавитов.
![]()
Выше – часть Windows 1251. Соответствующий фрагмент отображает кириллические компоненты и другие составляющие.
Двоичный код
Самый широко используемый метод кодирования информации – двоичное кодирование. Кодирование данных двоичным кодом применяется во всех современных технологиях.
![]()
Двоичный (бинарный) код — последовательность нолей и единиц. Это универсальный способ отображения любых информационных сведений (текстовых сообщений, картинок, звуковых и видеоматериалов). Сведения, закодированные в бинарном коде, очень удобно хранить, обрабатывать и передавать с одного электронного устройства на другое, в чем и заключается преимущества использования двоичного кодирования информации.
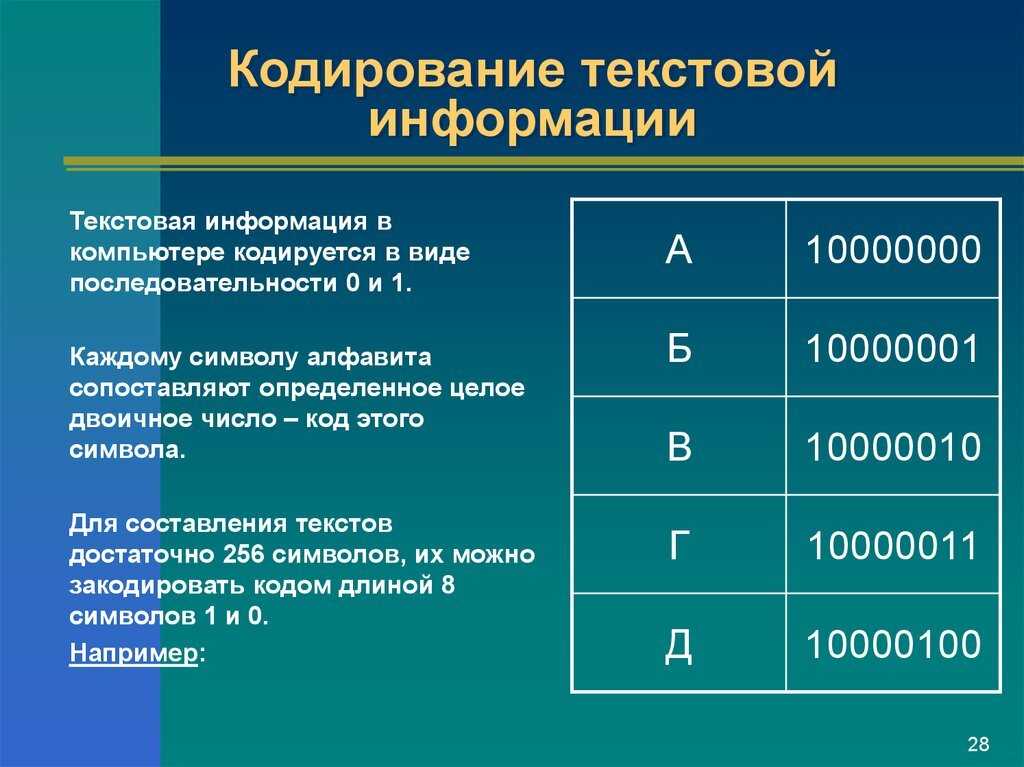
Двоичное кодирование информации применяется для различных данных:
- двоичное кодирование текстовой информации заключается в присвоении буквенным, цифровым и другим обозначениям определенного кода. Он записывается в компьютерной памяти цепочкой из нулей и единиц. Порядок кодирования алфавита в двоичный код с помощью стандарта ASCII является наглядным примером;
- вид используемой графики влияет на то, каким образом производится двоичное кодирование графической информации;
- двоичное кодирование звуковой информации происходит после дискретизации звуковой волны и присвоения каждому компоненту соответствующего бинарной цепочки чисел;
- кодирование двоичным кодом видеоматериалов сочетает принципы работы со звуком и растровыми изображениями.
Кодирование числовой информации
При кодировании чисел учитывается цель, с которой цифра была введена в систему: для арифметических вычислений или просто для вывода. Все данные, кодируемые в двоичной системе, шифруются с помощью единиц и нолей. Эти символы еще называют битами. Этот метод кодировки является наиболее популярным, ведь его легче всего организовать в технологическом плане: присутствие сигнала – 1, отсутствие – 0. У двоичного шифрования есть лишь один недостаток – это длина комбинаций из символов. Но с технической точки зрения легче орудовать кучей простых, однотипных компонентов, чем малым числом более сложных.
Целые числа кодируются просто переводом чисел из одной системы счисления в другую. Для кодирования действительных чисел используют 80-разрядное кодирование. При этом число преобразуют в стандартный вид.
Что такое двоичный код
Когда мы говорим о двоичном коде, мы должны сначала разобраться в понятии «бит». Бит (сокращение от binary digit) представляет собой самую маленькую единицу информации. Он может принимать значение либо 0, либо 1. Используя комбинацию битов, можно представлять различные виды информации: числа, символы (буквы, знаки препинания, спецсимволы и т. д.), изображения, звуки и т. д.
Принцип работы современных компьютеров также имеет двоичную природу. Носителем информации в них является электрический заряд или импульс. Например, оперативная память содержит в себе множество ячеек, в которых этот заряд может либо отсутствовать, либо присутствовать, что соответствует 0 и 1. Комбинации таких ячеек с отсутствием или присутствием электрического заряда и являются физическим кодированием информации. Аналогично данные сохраняются на SSD, flash-картах. А вот на магнитных жестких дисках роль мельчайшего физического носителя информации играет ячейка из ферромагнетика, которая также принимает одно из двух состояний — намагниченное или ненамагниченное. Считывая информацию с жесткого диска специальной головкой, компьютер переводит это состояние в соответствующий электрический сигнал.
Иными словами, непосредственно в электронных вычислительных устройствах кодирование информации осуществляется с помощью бинарных пар состояний различных физических сущностей (электрического заряда или импульса, намагничивания и т. д.). А цифровой бинарный код — те самые 0 и 1 — это абстрактная двоичная запись таких состояний.